背景
一直以来都是自己一个人玩吉他。最开始是指弹,一个人即是正义。后来接触电吉他,渐渐觉得和别人一同演奏也是很愉悦的事情。转行后第一份工作稳定下来之后,又搞了把电吉他自娱自乐,有一天突然就想看能不能找一个业余乐队,周末一起high。
怎么找呢,线下没明显的途径,线上无非豆瓣、贴吧、企鹅群,最终我选择了豆瓣。于是先上豆瓣,搜“乐队”,在小组分类下,找几个合适(主要是人多)的小组点进去,找上海地区乐队招吉他手的相关帖子,再打开看详情,乐队风格对不对味,对成员有没有硬性要求等。把每个小组里的前几页都翻了一遍,只找到一个合适的,但帖子发的早,人家已经不招了。之后的一段时间,每天或者隔几天晚上下班后都会重复上面的步骤,不同的是,只需要关注第一页前几篇。
这样重复了几次,感觉太蠢。重复性的筛选+豆瓣+会点python,自然想到爬虫。再加上买了云服务器,可以配置cron定时运行爬虫脚本,并把更新的结果用邮件通知到我。
码起来
main函数
代码即整体思路:
def main():
result = [] #初始化结果数组
for group in GROUPS: #循环处理每个小组(首页)链接
posts = getPosts(group) #获取当前小组的所有帖子,每个结果包含帖子标题和帖子链接
result += myFilter(posts) #筛选帖子,结果追加至结果数组
if len(result) > 0:
record(result) #当结果数组不为空时,记录并通知
获取
爬虫的核心,没什么特殊的
import requests
from bs4 import BeautifulSoup as bs
def getPosts(group):
r = requests.get(group)
ans = []
if (r.status_code == 200):
soup = bs(r.text, 'html.parser')
ans = soup.select('table.olt tr')
return ans
筛选
我的过滤条件是这样的:
1. 置顶帖不看
2. 标题包含“上海+乐队”或“上海+吉他”或“日系+吉他”这样的关键词组合, 同时不包含“金属”,“核”,“视觉”中的任何一个关键词
个人喜好,求同存异
KW_SETS = [ #包含关键词组合的list, 每个关键词组合也是一个list
'上海 吉他'.split(' '),
'上海 乐队'.split(' '),
'日系 吉他'.split(' '),
]
EXCLUDE = '金属 核 视觉'.split(' ')
def judge(title): #对帖子标题进行关键词/排除词检查
for ex in EXCLUDE:
if title.find(ex) > -1:
return False #只要发现需要排除的关键词就返回False
hasOne = False #记录是否在KW_SETS中匹配到至少一个关键词组合
for kw_set in KW_SETS:
flag = True #记录某个关键词组合中的关键词是否全部被包含
for kw in kw_set:
flag = flag and title.find(kw) > -1
hasOne = hasOne or flag
return hasOne
def myFilter(posts):
ans = []
for post in posts:
title = post.select('td.title') #获取到的是一个list
if title:
if title[0].select('span.pl'): #找到这个元素就说明是置顶帖,跳过
continue
a = title[0].find('a') #获取到包含标题和链接的a标签, 可能为空
if a and judge(a.attrs['title']):
#标题存在且符合要求, 记入结果
ans.append({'title': a.attrs['title'], 'href': a.attrs['href']})
return ans
记录及通知
代码略有点长,整体思路就是先尝试读取已有的(上一次的)记录文件,然后比较上一次的记录和本次记录,如果本次记录里有“新发现”,再执行写入及通知操作。
import os, json, smtplib
from email.mime.text import MIMEText
from email.header import Header
RECORD = 'record.json' #记录文件的文件名
SENDMAIL = True #是否发送邮件通知, 调试非邮件部分时我会设为False
def record(result):
doWrite = False #是否写入记录并通知
if os.path.isfile(RECORD): #存在已有的记录文件
with open(RECORD, 'r') as r: #读取记录文件
try:
inPut = json.loads(r.read()) #转为list
except:
inPut = []
if len(inPut) > 0:
for res in result:
found = False #当前条目res是否能在上次的记录中找到,即是否有“新发现”
for old in inPut: #内层循环将当前条目res与上次记录的所有条目逐一比对
if res['href'] == old['href']: #判断依据是链接地址
found = True #找到,做好标记并退出内层循环
break
if not found:
doWrite = True #只要有一个“新发现”即可退出外层循环
break
else:
doWrite = True #上一次的记录为空或格式有误
else:
doWrite = True #上一次的记录不存在
if doWrite:
print('something new, recording')
outPut = json.dumps(result, sort_keys=True, indent=4, ensure_ascii=False) #将本次记录list格式化为json字符串
with open(RECORD, 'w') as w:
try:
w.write(outPut) #写入记录文件
except Exception as e:
print(e)
if SENDMAIL:
addr = 'username@sina.com'
server = smtplib.SMTP('smtp.sina.com', 587)
server.starttls()
server.set_debuglevel(1)
server.login(addr, 'password')
html = '<html><body><ol>'
for r in result:
html += '<li><a href="'+r['href']+'">'+r['title']+'</a></li>'
html += '</ol></body></html>'
msg = MIMEText(html, 'html', 'utf-8')
msg['From'] = Header(addr)
msg['Subject'] = Header('News on your interest', 'utf-8')
server.sendmail(addr, [addr], msg.as_string())
server.quit()
else:
print('nothing new')
发送邮件部分基本就是照搬廖雪峰的教程,所以不作注释了。smtp端口配置可能因邮件服务商而异,我一开始用的是163邮箱,25端口,在本地测试可以发送成功,放到阿里云上就不行了,尝试别的端口也不行。最后用新浪邮箱成功了。另外邮件头信息里一定要有From,且与发件人实际邮箱地址一致,否则也发不出去。
发送邮件一开始打算是用cron自带的发送邮件功能,那样的话需要通过bash脚本实现判断是否有“新发现”,方法是执行python脚本前获取记录文件的修改日期,执行后再获取一次,两者不相等就说明python脚本有写入操作,即有新发现。后来才突然想起python本身就可以发送邮件。
另外新旧记录比对的部分,一开始的思路是按每行一个条目的规则写入,读取时一行行读入字符串,与本次记录比对。后来才想到json这个标准库,方便了不少。
bash脚本
不在bash脚本里判断是否有“新发现”的话就简单了:
# run.sh
`/usr/bin/python3 crawl.py > log.txt`
前面的’/usr/bin/python3’是python3的可执行文件路径,如果命令行输入python打开的就是python3的话就只写’python’即可。后面加一个’> log.txt’会把python脚本执行过程中的屏幕输出(print输出、报错信息等)写入到log.txt中。写入是覆盖写入,也就是只能记录前一次的屏幕输出,不过也够了。
之后需要为当前用户添加该脚本的执行权限,命令行输入:
chmod +x run.sh
cron配置
直接编辑/etc/crontab:
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# 不发送邮件加入这一行:
MAILTO=""
# m h dom mon dow user command
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
47 6 * * 7 root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )
52 6 1 * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )
# 以上为系统自带任务,加入一行:
0 18 * * * pixel export LANG="en_US.UTF-8"; cd /home/pixel/python/crawl_douban && ./run.sh
#
每天18点执行一次。注意首先要cd到python脚本所在目录,再执行bash脚本。另外在我电脑上测试时,前面那句 export LANG="en_US.UTF-8"; 是必须的,否则python执行时会报错:’ascii’ codec can’t encode characters in position 91-94: ordinal not in range(128),而直接从命令行运行python脚本不会报错。搜了好几种解决方案,最后只有这个管用。但是放到我的服务器上运行并不需要这句,好像和系统编码有关,不深究了。
之后重新载入cron服务:
service cron reload
成果
开始定时任务之后,第一个18点我收到了第一封邮件,之后只会在有新帖出现后收到新邮件。到目前为止,任务跑了半个多月,只有一次更新。
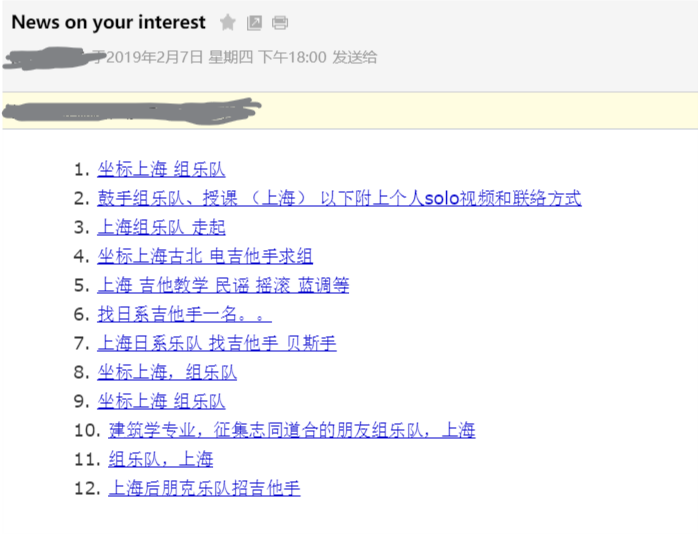
邮件里链接直达比较方便,不方便的是一眼看不出哪个是新帖,之后再改。